「深度学习」Attention? Attention!
最近两年,注意力模型(Attention Model)被广泛使用在自然语言处理、图像识别及语音识别等各种不同类型的深度学习任务中,是深度学习技术中最值得关注与深入了解的核心技术之一。因此,了解注意力机制的工作原理对于希望在深度学习领域深耕的技术人员来说有很大的的必要。
0x00 Intro to Attention
Attention 机制最早是针对序列模型提出的,出处是Bengio大神在2015年的这篇论文:
《Neural Machine Translation by jointly learning to align and translate, Bengio et. al. ICLR 2015》
从注意力模型的命名方式看,很明显其借鉴了人类的注意力机制。因此,我们首先简单介绍「人类视觉的选择性注意力机制」。
视觉注意力机制是人类视觉所特有的大脑信号处理机制。人类视觉通过快速扫描全局图像,获得需要重点关注的目标区域,也就是一般所说的注意力焦点,而后对这一区域投入更多注意力资源,以获取更多所需要关注目标的细节信息,而抑制其他无用信息。
这是人类利用有限的注意力资源从大量信息中快速筛选出高价值信息的手段,是人类在长期进化中形成的一种生存机制,人类视觉注意力机制极大地提高了视觉信息处理的效率与准确性。
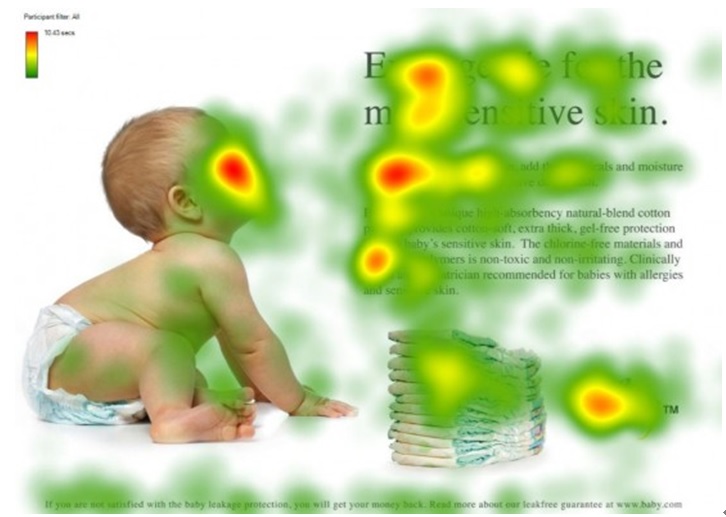
图1形象化展示了人类在看到一副图像时是如何高效分配有限的注意力资源的,其中红色区域表明视觉系统更关注的目标。很明显,对于图1所示的场景,人们会把注意力更多投入到人的脸部,文本的标题以及文章首句等位置。

同样地,在自然语言处理中,我们也可以用注意力机制解释一句话或者上下文中词与词之间的关系。如图2,当看到“eating”这个词时,我们会期望在后面不远的位置看到“食物“描述的词。下图中有色词表示食物,但并不是每个词都与”eating“直接强相关。
深度学习中的注意力机制从本质上讲和人类的选择性视觉注意力机制类似,核心目标也是从众多信息中选择出对当前任务目标更关键的信息。简而言之,在预测或推断一个元素时,如图片中的像素点或句中的一个词,我们使用「注意力向量」来判断它与其他元素有多强的关联性,然后对加权后的向量求和以逼近最后的目标值(target)。
0x01 Encoder-Decoder Framework
在继续介绍深度学习中的注意力机制之前,我们不得不先谈谈seq2seq模型与Encoder-Decoder框架。
Seq2Seq模型诞生于语言模型领域(Sutskever, et al. 2014)—— 广泛的讲,它是将一个输入序列(source)转化为另一个序列(target),两个序列都可以是不定长的。转化任务的场景包括多语言机器翻译(文本或语音)、问答对话对话生成系统、甚至是句子解析为语法树。
Seq2Seq模型一般都会包含 Encoder-Decoder 结构,包括:
- Encoder——处理输入序列并将信息压缩到一个固定长度的上下文向量中(sentence embedding 或者 context vector)。上下文向量被当做是输入序列的语义概要。
- Decoder——由上下文向量初始化,并每次产生一个转码输出。
其中,编码器和解码器都是循环神经网络结构,如LSTM或者GRU单元。
图2是Encoder-Decoder框架的一种抽象表示:

在自然语言处理领域中,我们的目标是给定输入句子 $X$ ,经过 Encoder-Decoder 后生成目标句子 $Y$ 。 $X$ 和 $Y$ 分别由各自的单词序列组成,长度分别为 $m$ 和 $n$ :
$$X = <x_1, x_2, …, x_m>$$
$$Y = <y_1, y_2, …, y_n>$$
首先由 Encoder 对输入句子 $X$ 进行编码,将输入句子通过非线性变换转化为中间语义表 $C$ :
$$C = F(x_1, x_2, …, x_m)$$
Decoder的任务则是根据句子 $X$ 的中间语义表示 $C$ 和之前已经生成的历史信息 $y_1, y_2, …, y_{i-1}$ 来生成 $i$ 时刻要生成的单词 $y_i$ 。
$$y_i = G(C, y_1, y_2, …, y_{i-1})$$
依次产生每个 $y_i$ 即可得到最后的输出句子 $Y$ 。其中,$X$ 和 $Y$ 可以是同一种语言,也可以是不同的语言。

实际上,Encoder-Decoder框架不仅仅在文本领域广泛使用,在语音识别、图像处理等领域也经常使用。
- 比如对于语音识别来说,图2所示的框架完全适用,区别无非是Encoder部分的输入是语音流,输出是对应的文本信息;
- 而对于“图像描述”任务来说,Encoder部分的输入是一副图片,Decoder的输出是能够描述图片语义内容的一句描述语。
一般而言,文本处理和语音识别的Encoder部分通常采用RNN模型,图像处理的Encoder一般采用CNN模型。
0x02 Why Attention?
上一节提到的 Encoder-Decoder 框架可以看作是一种「注意力不集中的分心模型」。
为什么说它注意力不集中呢?
$$y_1 = F(C)$$
$$y_2 = F(C, y_1)$$
$$y_3 = F(C, y_1, y_2)$$
由于上下文向量 $C$ 是由输入句子 Source 的每个单词经过 Encoder 编码产生的,这就意味着不论是生成哪个单词 $y_1, y_2$ 还是 $y_3$ ,Source中任意单词 $x_i$ 对生成某个目标单词 $y_i$ 来说影响力都是相同的。这就类似于人类看到眼前的画面,但是眼中却没有注意焦点一样。
如果拿机器翻译来解释这个分心模型可能更好理解一些。比如输入句子 Source 为 “Tom chases Jerry.” ,通过 Encoder-Decoder 框架逐步生成中文单词 [“汤姆”、“追逐”、“杰瑞”] 。
在翻译“杰瑞”这个中文单词的时候,分心模型里面的每个英文单词对于翻译目标单词“杰瑞”贡献是相同的,很明显这里不太合理,因为显然 “Jerry” 对于翻译成 “杰瑞” 更重要,但是分心模型是无法体现这一点的,这就是为何说它没有体现注意力的原因。
除此之外,固定长度的上下文向量具有一个明显的致命缺点——无法记忆长句子。因为 Decoder 在生成每个输出单词 $y_i$ 时都需要之前输出的单词 $y_1, y_2, …, y_{i-1}$ 作为输入,当句子比较长时,前面的信息将会随着RNN的传导慢慢丢失。
这也是为什么要引入注意力机制的重要原因。
0x02 Attention Mechanism
在本节我们将首先从概念上对 Attention 有一个直观地认识,然后将从理论的角度出发来定义注意力机制,紧接着我们尝试跳出 Encoder-Decoder 框架再来看 Attention 的本质思想,最后简要介绍一下 Attention 家族中的不同类别。
1. 初识 Attention
在刚刚提到的例子中,如果引入Attention模型的话,应该在翻译“汤姆”的时候,体现出每个英文单词对于翻译当前中文单词不同的影响程度。比如给出一个类似下面的概率分布:
| x1: Tom | x2: chases | x3: Jerry | |
|---|---|---|---|
| C1: “汤姆” | 0.5 | 0.2 | 0.3 |
每个概率代表了翻译当前中文单词“汤姆”时,注意力模型分配给不同英文单词的注意力大小。
同理,目标句子中的每个单词都应该学会其对应的输入句子中单词的注意力分配信息,这就意味着在生成每个单词 $y_i$ 的时候,原来固定的上下文向量 $C$ 被替换成会根据当前生成单词而不断变化的 $C_i$ 。
如果把 $C_1, C_2, C_3$ 拼接在一起,就得到了一个注意力分配矩阵:
| x1: Tom | x2: chases | x3: Jerry | |
|---|---|---|---|
| C1: “汤姆” | 0.7 | 0.1 | 0.2 |
| C2: “追逐” | 0.3 | 0.6 | 0.2 |
| C3: “杰瑞” | 0.2 | 0.1 | 0.7 |
理解Attention机制的关键就在这里,在得到这样一个注意力分布矩阵后,生成输出单词的过程本质上就是做一个加权求和的操作。
引入了注意力机制的 Encoder-Decoder 框架可以抽象成图4:

下面这张动图能很好地说明注意力机制的工作过程:

现在,我们已经对深度学习中的注意力机制有了一个很直观的认识了。但还有一个问题,怎么得到上面的「注意力分布矩阵」呢?请接着往后阅读。
2. 从数学的角度看 Attention
在这一节,我们将从理论的角度出发来定义注意力机制。
我们用 $X$ 表示长度为 $n$ 的源输入序列,用 $Y$ 表示长度为 $m$ 的目标输出序列:
$$X = [x_1, x_2, \dots, x_n]$$
$$Y = [y_1, y_2, \dots, x_m]$$
Encoder是一个双向RNN结构 —— 包括前向和后向隐藏层状态,对其进行简单的维度拼接即可表示输入序列的隐藏状态,且同时考虑了上下文信息 :
$$\boldsymbol{h}_i = [\overrightarrow{\boldsymbol{h}}_i \ ; \overleftarrow{\boldsymbol{h}}_i], i=1, \dots, n$$
Decoder在 $t$ 时刻有隐藏状态 $s_t$ ,并接受上一时刻的隐藏状态 $s_{t-1}$ ,上一个输出 $y_{t-1}$ 和上下文向量 $\mathbf{c}_t$ 作为输入:
$$s_t = f(s_{t-1}, y_{t-1}, \mathbf{c}_t), \ t = 1, 2, \dots, m$$
其中,上下文向量 $\mathbf{c}_t$ 是输入序列的隐藏状态 $h_i$ 之和,并由对齐模块进行加权 :
$$c_t = \sum_{i=1}^n \alpha_{t,i} h_i$$
$$\alpha_{t,i} = \text{align}(y_t, x_i) = \frac{\exp(\text{score}(s_{t-1}, h_i))}{\sum_{i’=1}^n \exp(\text{score}(s_{t-1}, h_{i’}))}$$
$$\begin{aligned} \mathbf{c}t &= \sum{i=1}^n \alpha_{t,i} \boldsymbol{h}i & \small{\text{; Context vector for output }y_t}\ \alpha_{t,i} &= \text{align}(y_t, x_i) & \small{\text{; How well two words }y_t\text{ and }x_i\text{ are aligned.}}\ &= \frac{\exp(\text{score}(\boldsymbol{s}{t-1}, \boldsymbol{h}i))}{\sum{i’=1}^n \exp(\text{score}(\boldsymbol{s}{t-1}, \boldsymbol{h}{i’}))} & \small{\text{; Softmax of some predefined alignment score.}}. \end{aligned}$$
由定义可以看出,对齐模块会针对第 $i$ 个输入序列和第 $t$ 个输出序列计算一个相关性权重 $\alpha_{t,i}$ ,以评判 $(y_t, x_i)$ 的对齐效果,整个 $\alpha_{t,i}$ 集合衡量了与每个输出对应的输入隐藏状态的重要性有多大,或相关性有多强。
关于对齐得分向量 $score$ ,在Bahdanau的文章中,它是由单个隐藏层的前向网络(feed-forward network)来生成的,并和整个网络的其他部分进行联合训练。$score$ 的计算方式如下:
$$score(s_t,h_i)=V^\top_atanh(W_a[s_t \ ; h_i])$$
这一步得到的「对齐得分矩阵」是一个很好的副产物,它能够可视化的表示每个输入序列和输出序列的关联程度。

3. Attention 的本质思想
剥离 Encoder-Decoder 框架来看看 Attention
如果把Attention机制从Encoder-Decoder框架中剥离,并进一步做抽象,可能更容易掌握 Attention机制的本质思想。

如果把 Source 看成是由一系列的 $<Key, Value>$ 数据对构成,那么给定 Target 中某个元素 Query,通过计算 Query 和各个 Key 之间的相关性,便可得到每个 Key 对应 Value 的权重系数,然后对 Value 进行加权求和,就得到了 Query 对应的 Attention 值。
简而言之,本质上 Attention 机制就是对Source中元素的Value值进行加权求和,而Query和Key用来计算对应Value的权重系数。因而可以将注意力抽象成如下公式:
$$Attention(Query, Source) = \sum^{L_x}_{i=1} Similarity(Query, Key_i) * Value_i$$
从图8可以引出对 Attention 的另外一种理解 —— 软寻址(Soft Addressing):
Source 可以看成是存储器,由地址Key和对应的值Value组成;
当有个查询请求Query时,需要对Query和地址Key进行相似性计算来寻址;
之所以说是软寻址,是因为它不像一般寻址那样只从存储器的对应地址中找出一个Value,而是从每个地址Key都会取出Value,取出Value的重要性根据Query和Key的相似性来决定,然后对取出的Value进行加权求和,这样就可以得到最终的 Attention 。
关于 Attention 的具体计算过程
关于 Attention 机制的具体计算过程,可以大致将其归纳为两个过程、三个阶段:
根据 Query 和 Key 计算权重系数;
1)根据 Query 和 Key 计算两者的相似性或相关性;
2)对原始分支进行归一化处理;
根据权重系数对 Value 进行加权求和。
整个过程如图9所示:

在阶段1,可以使用不同的计算机制来衡量 $Query$ 和某个 $Key_i$ 之间的相似性或者相关性。其中,最常见的方法包括:
- 求向量点积:$Similarity(Query, Key_i) = Query \cdot Key_i$
- 求Cosine相似性:$Similarity(Query, Key_i) = \frac{Query \ \cdot \ Key_i}{||Query|| \ \cdot \ ||Key_i||}$
- 引入 Feed-Forward Network:$Similarity(Query, Key_i) = MLP(Query, Key_i)$
由于在阶段1产生的分值范围会根据不同计算机制而不同,因此在阶段2使用softmax来进行归一化,不仅能将原始计算分值归约成所有元素权重之和为1的概率分布,也能够通过softmax的内在机制更加突出重要元素的权重:
$$\alpha_i = softmax(s_i) = \frac{e^{s_i}}{\sum^{L_x}_{j=1}e^{s_j}}$$
最后在阶段3对Value进行加权求和即可得到最终的 Attention 数值:
$$Attention(Query, Source) = \sum^{L_x}_{i=1} \alpha_i \cdot Value_i$$
通过如上三个阶段的计算,即可求出针对Query的Attention数值,目前绝大多数注意力机制都符合上面的抽象计算过程。
4. Attention 家族
本节主要介绍一些更广泛意义上的 Attention 类型。
3.1 概要
| Name | Alignment score function | Citation |
|---|---|---|
| Content-base attention | $score(s_t,h_i) = cosine[s_t, h_i]$ | Graves2014 |
| *Additive()** | $score(s_t,h_i)=V^\top_atanh(\boldsymbol{W}_a[\boldsymbol{s}_t \ ; \boldsymbol{h}_i])$ | Bahdanau2015 |
| Location-Base | $\alpha_{t,i} = softmax(\boldsymbol{W}_a \boldsymbol{s}_t)$ Note: This simplifies the softmax alignment to only depend on the target position. |
Luong2015 |
| General | $score(s_t,h_i) = \boldsymbol{s}^\top_t\boldsymbol{W}_a\boldsymbol{h}_i$ where $\boldsymbol{W}_a$ is a trainable weight matrix in the attention layer. |
Luong2015 |
| Dot-Product | $score(s_t,h_i) = \boldsymbol{s}^\top_t\boldsymbol{h}_i$ | Luong2015 |
| Scaled Dot-Product(^) | $score(s_t,h_i) = \frac{\boldsymbol{s}^\top_t\boldsymbol{h}_i}{\sqrt{n}}$ Note: very similar to the dot-product attention except for a scaling factor; where n is the dimension of the source hidden state. |
Vaswani2017 |
(*) Referred to as “concat” in Luong, et al., 2015 and as “additive attention” in Vaswani, et al., 2017.
(^) It adds a scaling factor $\frac{1}{\sqrt{n}}$ , motivated by the concern when the input is large, the softmax function may have an extremely small gradient, hard for efficient learning.
下面总结了一些更加广泛的注意力机制的类别:
| Name | Definition | Citation |
|---|---|---|
| Self-Attention(&) | Relating different positions of the same input sequence. Theoretically the self-attention can adopt any score functions above, but just replace the target sequence with the same input sequence. | Cheng2016 |
| Global/Soft | Attending to the entire input state space. | Xu2015 |
| Local/Hard | Attending to the part of input state space; i.e. a patch of the input image. | Xu2015; Luong2015 |
(&) Also, referred to as “intra-attention” in Cheng et al., 2016 and some other papers.
3.2 Self-Attention
Self-attention,又称 intra-attention,是一种提取单个序列表征的注意力机制,能够计算同一序列的不同位置之间关联程度。自注意力机制已经被证明在机器阅读理解,抽象概要和图片描述生成等任务中非常有效。
在下面的样例中,自注意力机制能够学习到当前词和句子中前面的词的关联性。红色为当前词,蓝色阴影的大小表明了它们之间的关联程度(Image source: Cheng et al., 2016)。

3.3 Soft vs Hard Attention
在 show, attend and tell 这篇论文中,自注意力机制被应用在图片描述生成任务中。图片首先在 encoder 中被CNN编码,然后 LSTM decoder 会通过自注意力机制学习权重,并使用这些卷积特征逐个生成描述词。
下面注意力权重的可视化清晰地展示了模型每关注图像的一个区域都会输出一个对应的词,“A woman is throwing a frisbee in a park.” (Image source: Xu et al. 2015)。

这篇论文首次提出了 ”柔性“ 与 ”刚性“ 注意力的区别 —— 基于注意力是否需要处理整张图片还是仅仅局部一小块:
- 柔性注意力:对齐权重通过源图片所有的”patch“进行学习映射,本质上和 Bahdanau et al., 2015 的想法一致。
- Pro: 模型是平滑且可导的
- Con: 当输入图片很大时,训练代价很高
- 刚性注意力:每次仅选取图片中的一个”patch“
- Pro: 在inference阶段计算量更小
- Con: 模型是不可导的,需要更复杂的技术手段——如降低方差(variance reduction)或者强化学习去训练(Luong, et al., 2015)
3.4 Global vs Local Attention
Luong, et al., 2015 提出了”全局“和”局部“注意力的概念。
全局注意力和柔性注意力很相似;
局部注意力是”柔性“和”刚性“的糅合——相对于刚性,它通过改进使模型可导:
模型首先为当前目标词预测一个粗略的对齐位置,然后以源输入位置为中心,在这个中心窗口内计算上下文向量。

0x03 Self-Attention in Transformer
“Attention is All you Need” (Vaswani, et al., 2017) ,毫无疑问是2017年最有影响力和最有趣的论文之一,它对柔性注意力机制作出了许多改进,并使得无RNN单元的 seq2seq 建模成为可能,其提出的 transformer 模型完全建立在自注意力机制上。
Transformer 的主要部件是 multi-head self-attention mechanism 。
- 在Encoder中,它将输入序列的编码表示看作 Key-Value 对,均为n维(n为输入序列长度);
- 在Decoder中,先前时刻的输出被压缩到一个 Query 中(m维),然后通过把这个 Query 映射到 Key-Value 的集合来产生当前时间步的输出。
Transformer采用了 scaled dot-product attention :输出为 Value 的加权求和,其中分配给每一项的权重由 Query 和Key 点积求得。因此,可以将其抽象为如下公式:
$$Attention(Q, K, V) = softmax(\frac{Q \cdot K^\top}{\sqrt{n}}) \cdot V$$
此外,Transformer 还采用了多头注意力机制,即不是只计算一次注意力,而是并行地多次运行 scaled 点积注意力,并将计算结果 concat 起来通过一个 Linear 层转化成期望的维度。

因此,可进一步将其抽象为如下公式:
$$MultiHead(Q, K, V) = [head_1; \dots ; head_h] W^O$$
其中 $head_i = Attention(Q \cdot W^Q_i, K \cdot W^K_i, V \cdot W^V_i)$ ,$W^Q_i, W^K_i, W^V_i$ 以及 $W^O$ 均为可学习参数矩阵。
Transformer的简单介绍到此为止,如需更进一步了解,请移步「深度学习」Transformer 模型详解 。
0x04 Implement Self-Attention using Pytorch
在本节,我们将使用 pytorch 实现一个简单的自注意力模型,其中:
dim_in表示embedding 维的特征长度E ;- Q 和 K 的维度相等且等于输入序列长度S,用
dim_k表示,并使用 scaled-dot 函数衡量 Q 和 K 之间的相似性; dim_v等于输出序列长度T ;- 输入特征矩阵
x的维度为 (N, S, E) ;
1 | from math import sqrt |
这里为简单起见没有实现mask,若要实现,则在softmax前把需要mask的位置加上-np.Inf就可以了,这样两个Tensor进行矩阵乘法后,在需要mask掉的位置的分数就是负无穷,softmax后的注意力分布就是0。
Reference
[3] 计算机视觉中的注意力机制
[4] 详解深度学习中“注意力机制”
[6] 自注意力机制的PyTorch实现




